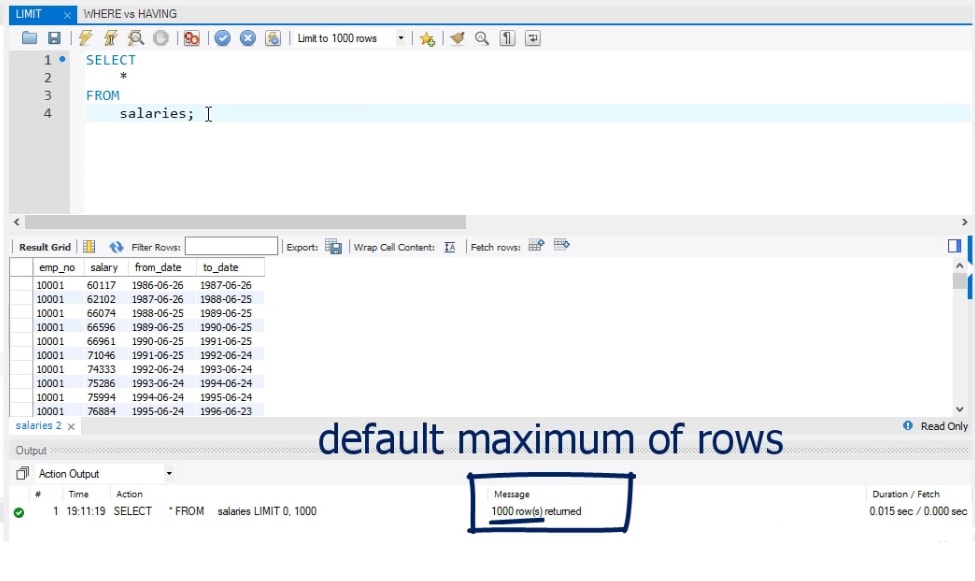
Though both are used to exclude rows from the result set, you should use the WHERE clause to filter rows before grouping and use the HAVING clause to filter rows after grouping. In other words, WHERE can be used to filter on table columns while HAVING can be used to filter on aggregate functions like count, sum, avg, min, and max. Expression_n Expressions that are not encapsulated within an aggregate function and must be included in the GROUP BY Clause at the end of the SQL statement. Aggregate_function This is an aggregate function such as the SUM, COUNT, MIN, MAX, or AVG functions. Aggregate_expression This is the column or expression that the aggregate_function will be used on.
There must be at least one table listed in the FROM clause. These are conditions that must be met for the records to be selected. The expression used to sort the records in the result set. If more than one expression is provided, the values should be comma separated.
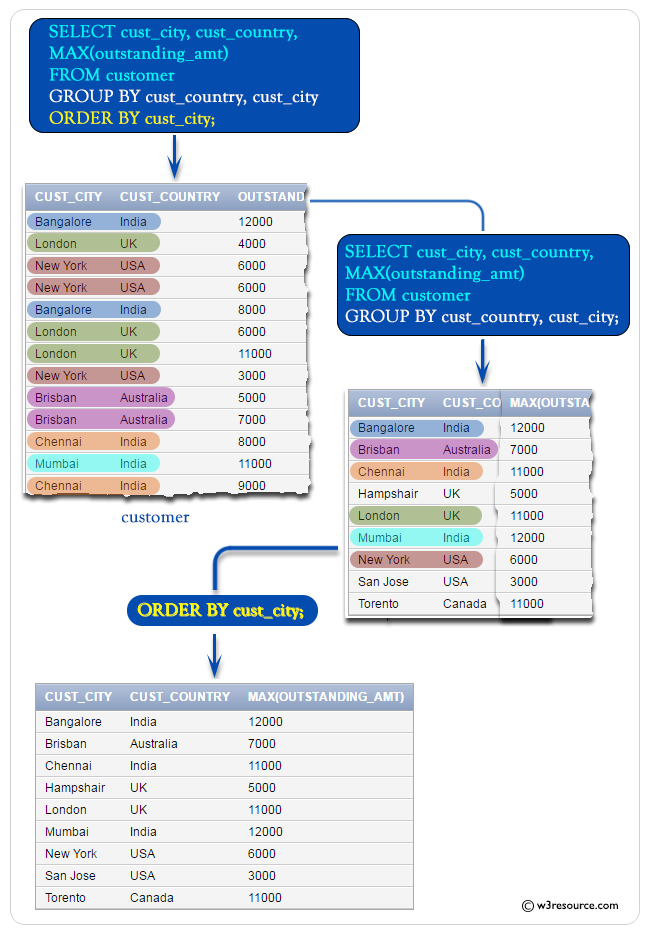
ASC sorts the result set in ascending order by expression. DESC sorts the result set in descending order by expression. We can often use this clause in collaboration with aggregate functions like SUM, AVG, MIN, MAX, and COUNT to produce summary reports from the database. It's important to remember that the attribute in this clause must appear in the SELECT clause, not under an aggregate function. As a result, the GROUP BY clause is always used in conjunction with the SELECT clause. The query for the GROUP BY clause is grouped query, and it returns a single row for each grouped object.

SQL Inner Join permits us to use Group by clause along with aggregate functions to group the result set by one or more columns. Group by works conventionally with Inner Join on the final result returned after joining two or more tables. If you are not familiar with Group by clause in SQL, I would suggest going through this to have a quick understanding of this concept. Below is the code that makes use of Group By clause with the Inner Join. At a high level, the process of aggregating data can be described as applying a function to a number of rows to create a smaller subset of rows. In practice, this often looks like a calculation of the total count of the number of rows in a dataset, or a calculation of the sum of all of the rows in a particular column.

Can We Use Group By Without Where Clause In Sql For a more comprehensive explanation of the basics of SQL aggregate functions, check out the aggregate functions module in Mode's SQL School. ROLLUP is an extension of the GROUP BY clause that creates a group for each of the column expressions. Additionally, it "rolls up" those results in subtotals followed by a grand total. Under the hood, the ROLLUP function moves from right to left decreasing the number of column expressions that it creates groups and aggregations on. Since the column order affects the ROLLUP output, it can also affect the number of rows returned in the result set. The GROUP BY clause is often used in SQL statements which retrieve numerical data.

It is commonly used with SQL functions like COUNT, SUM, AVG, MAX and MIN and is used mainly to aggregate data. Data aggregation allows values from multiple rows to be grouped together to form a single row. The first table shows the marks scored by two students in a number of different subjects.

Spark also supports advanced aggregations to do multiple aggregations for the same input record set via GROUPING SETS, CUBE, ROLLUP clauses. The grouping expressions and advanced aggregations can be mixed in the GROUP BY clause and nested in a GROUPING SETS clause. See more details in the Mixed/Nested Grouping Analytics section. When a FILTER clause is attached to an aggregate function, only the matching rows are passed to that function. This article explains the complete overview of the GROUP BY and ORDER BY clause. They are mainly used for organizing data obtained by SQL queries.

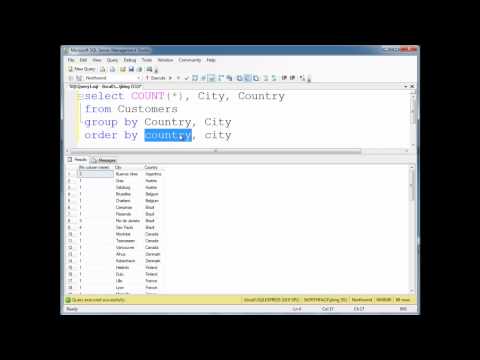
The difference between these clauses is one of the most common places to get stuck when learning SQL. The main difference between them is that the GROUP BY clause is applicable when we want to use aggregate functions to more than one set of rows. The ORDER BY clause is applicable when we want to get the data obtained by a query in the sorting order. Before making the comparison, we will first know these SQL clauses. The Group by Clause in SQL Server is used to divide similar types of records or data as a group and then return.

If we use group by clause in the query then we should use grouping/aggregate function such as count(), sum(), max(), min(), and avg() functions. Incidentally, if you do not group the city column in your SQL statement, SQL returns an error. When you list columns with aggregate functions, you must include those columns in your GROUP BY clause. For instance, the following SQL statement will give you an error and tell you that you must include City in a GROUP BY clause. You must use the aggregate functions such as COUNT(), MAX(), MIN(), SUM(), AVG(), etc., in the SELECT query. The result of the GROUP BY clause returns a single row for each value of the GROUP BY column.

Like most things in SQL/T-SQL, you can always pull your data from multiple tables. Performing this task while including a GROUP BY clause is no different than any other SELECT statement with a GROUP BY clause. The fact that you're pulling the data from two or more tables has no bearing on how this works. In the sample below, we will be working in the AdventureWorks2014 once again as we join the "Person.Address" table with the "Person.BusinessEntityAddress" table.
I have also restricted the sample code to return only the top 10 results for clarity sake in the result set. The GROUP BY clause is a SQL command that is used to group rows that have the same values. Optionally it is used in conjunction with aggregate functions to produce summary reports from the database. The Group by clause is often used to arrange identical duplicate data into groups with a select statement to group the result-set by one or more columns. This clause works with the select specific list of items, and we can use HAVING, and ORDER BY clauses. Group by clause always works with an aggregate function like MAX, MIN, SUM, AVG, COUNT.
This syntax allows users to perform analysis that requires aggregation on multiple sets of columns in a single query. Complex grouping operations do not support grouping on expressions composed of input columns. Athena supports complex aggregations using GROUPING SETS, CUBE and ROLLUP.

GROUP BY GROUPING SETS specifies multiple lists of columns to group on. GROUP BY CUBE generates all possible grouping sets for a given set of columns. GROUP BY ROLLUP generates all possible subtotals for a given set of columns. The GROUP BY clause is often used with aggregate functions such as AVG(), COUNT(), MAX(), MIN() and SUM(). In this case, the aggregate function returns the summary information per group. For example, given groups of products in several categories, the AVG() function returns the average price of products in each category.

The above query includes the GROUP BY DeptId clause, so you can include only DeptId in the SELECT clause. You need to use aggregate functions to include other columns in the SELECT clause, so COUNT is included because we want to count the number of employees in the same DeptId. When you start learning SQL, you quickly come across the GROUP BY clause. Data grouping—or data aggregation—is an important concept in the world of databases. In this article, we'll demonstrate how you can use the GROUP BY clause in practice.
We've gathered five GROUP BY examples, from easier to more complex ones so you can see data grouping in a real-life scenario. As a bonus, you'll also learn a bit about aggregate functions and the HAVING clause. The GROUP BY clause arranges rows into groups and an aggregate function returns the summary (count, min, max, average, sum, etc.,) for each group. In the result set, the order of columns is the same as the order of their specification by the select expressions.
If a select expression returns multiple columns, they are ordered the same way they were ordered in the source relation or row type expression. The GROUP BY clause is used in a SELECT statement to group rows into a set of summary rows by values of columns or expressions. Use theSQL GROUP BYClause is to consolidate like values into a single row.

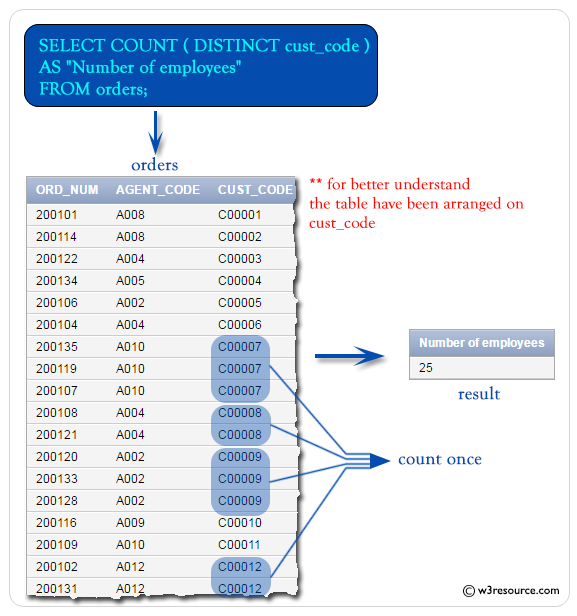
The group by returns a single row from one or more within the query having the same column values. Its main purpose is this work alongside functions, such as SUM or COUNT, and provide a means to summarize values. Here, you can add the aggregate functions before the column names, and also a HAVING clause at the end of the statement to mention a condition. The CityCount alias makes it easier to read, and you can use these column names in your report. Notice that the Atlanta and Dallas cities are only listed once in the result set even though it's in two records. The COUNT column tells you that the city is recorded twice, and then shows you only the city once because you grouped your values.

What if we want to filter the values returned from this query strictly to start station and end station combinations with more than 1,000 trips? Since the SQL where clause only supports filtering records and not results of aggregation functions, we'll need to find another way. FILTER is a modifier used on an aggregate function to limit the values used in an aggregation. All the columns in the select statement that aren't aggregated should be specified in a GROUP BY clause in the query.
The SELECT statement used in the GROUP BY clause can only be used contain column names, aggregate functions, constants and expressions. It's the second part of the error what we are looking for (i.e. or be used in an aggregate function). In fact, there's a set of aggregate functions that databases offer us.
In PostgreSQL count() is one example we've already seen, but there's a lot more. All output expressions must be either aggregate functions or columns present in the GROUP BY clause. SQL allows the user to store more than 30 types of data in as many columns as required, so sometimes, it becomes difficult to find similar data in these columns.

Group By in SQL helps us club together identical rows present in the columns of a table. This is an essential statement in SQL as it provides us with a neat dataset by letting us summarize important data like sales, cost, and salary. You can query data from multiple tables using the INNER JOIN clause, then use the GROUP BY clause to group rows into a set of summary rows. This statement is used to group records having the same values. The GROUP BY statement is often used with the aggregate functions to group the results by one or more columns. The GROUP BY clause divides the rows returned from the SELECTstatement into groups.

For each group, you can apply an aggregate function e.g.,SUM() to calculate the sum of items or COUNT()to get the number of items in the groups. However, you can use the GROUP BY clause with CUBE, GROUPING SETS, and ROLLUP to return summary values for each group. Adding a HAVING clause after your GROUP BY clause requires that you include any special conditions in both clauses.
If the SELECT statement contains an expression, then it follows suit that the GROUP BY and HAVING clauses must contain matching expressions. It is similar in nature to the "GROUP BY with an EXCEPTION" sample from above. In the next sample code block, we are now referencing the "Sales.SalesOrderHeader" table to return the total from the "TotalDue" column, but only for a particular year. In the sample below, we will return a list of the "CountryRegionName" column and the "StateProvinceName" from the "Sales.vSalesPerson" view in the AdventureWorks2014 sample database. In the first SELECT statement, we will not do a GROUP BY, but instead, we will simply use the ORDER BY clause to make our results more readable sorted as either ASC or DESC.

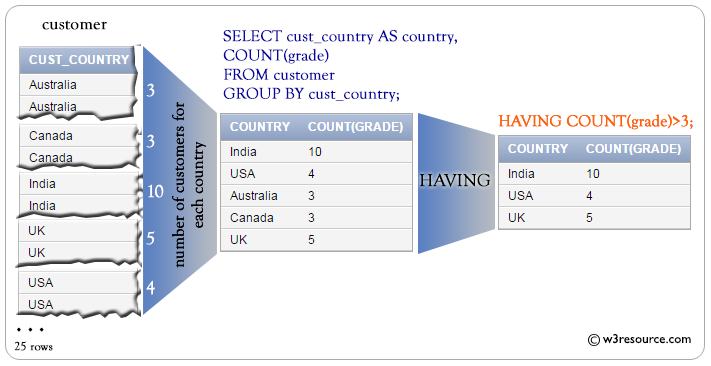
The HAVING keyword works exactly like the WHERE keyword, but uses aggregate functions instead of database fields to filter. UNION, INTERSECT, and EXCEPTcombine the results of more than one SELECT statement into a single query. ALL or DISTINCT control the uniqueness of the rows included in the final result set. Controls which groups are selected, eliminating groups that don't satisfy condition. This filtering occurs after groups and aggregates are computed. Grouping_expressions allow you to perform complex grouping operations.

You can use complex grouping operations to perform analysis that requires aggregation on multiple sets of columns in a single query. When a query has a GROUP BY, rather than returning every row that meets the filter condition, values are first grouped together. The rows returned are the unique combinations within the columns. The GROUP BY clause is used to get the summary data based on one or more groups. For example, the GROUP BY query will be used to count the number of employees in each department, or to get the department wise total salaries. In this lesson, we will learn uses of the GROUP BY clause in SQL.

GROUP BY is often used together with SQL aggregate functions like COUNT, SUM, AVG, MAX and MIN that act on numeric data. Together with these functions, the GROUP BY clause enhances the power of SQL and facilitates the creation of reports with summary data. Inner Join syntax basically compares rows of Table1 with Table2 to check if anything matches based on the condition provided in the ON clause. When the Join condition is met, it returns matched rows in both tables with the selected columns in the SELECT clause. Assume, we have two tables, Table A and Table B, that we would like to join using SQL Inner Join. The result of this join will be a new result set that returns matching rows in both these tables.

The intersection part in black below shows the data retrieved using Inner Join in SQL Server. Use the GROUP BY clause with aggregate functions in a SELECT statement to collect data across multiple records. An aggregate function performs a calculation on a group and returns a unique value per group. For example, COUNT() returns the number of rows in each group. Other commonly used aggregate functions are SUM(), AVG() , MIN() , MAX() . Contrary to what most books and classes teach you, there are actually 9 aggregate functions, all of which can be used with a GROUP BY clause in your code.

As we have seen in the samples above, you can have a GROUP BY clause without an aggregate function as well. As we demonstrated earlier in this article, the GROUP BY clause can group string values also, so it doesn't always have to be a numeric or date value. As you can see in the result set above, the query has returned all groups with unique values of , , and .

The NULL NULL result set on line 11 represents the total rollup of all the cubed roll up values, much like it did in the GROUP BY ROLLUP section from above. Another extension, or sub-clause, of the GROUP BY clause is the CUBE. The CUBE generates multiple grouping sets on your specified columns and aggregates them. In short, it creates unique groups for all possible combinations of the columns you specify. For example, if you use GROUP BY CUBE on of your table, SQL returns groups for all unique values , , and .

IIt is important to note that using a GROUP BY clause is ineffective if there are no duplicates in the column you are grouping by. A better example would be to group by the "Title" column of that table. The SELECT clause below will return the six unique title types as well as a count of how many times each one is found in the table within the "Title" column. In this lesson you learned to use the SQL GROUP BY and aggregate functions to increase the power expressivity of the SQL SELECT statement. You know about the collapse issue, and understand you cannot reference individual records once the GROUP BY clause is used. The GROUP BY statement is often used with aggregate functions (COUNT(),MAX(),MIN(), SUM(),AVG()) to group the result-set by one or more columns.